
Phân tích phương sai (ANOVA) là một phương pháp thống kê được sử dụng để kiểm tra xem liệu có hay không sự khác biệt giữa trung bình của một số nhóm (Dielman, 2001).
Mục tiêu của phân tích phương sai là so sánh trị số trung bình của nhiều nhóm (tổng thể) dựa trên các số trung bình của các mẫu quan sát từ các nhóm này và thông qua kiểm định giả thuyết để kết luận về sự bằng nhau của các số trung bình này. Trong nghiên cứu khoa học, phương pháp phân tích phương sai được dùng như là một công cụ để xem xét ảnh hưởng của một hay một số yếu tố nguyên nhân (định tính) đến một yếu tố kết quả (định lượng).
Các biến trong phân tích ANOVA gồm một biến phụ thuộc định lượng (Y) và nhiều biến độc lập (X) định tính.
MỘT SỐ GIẢ ĐỊNH KHI PHÂN TÍCH ANOVA
- Các nhóm so sánh phải độc lập và được chọn một cách ngẫu nhiên
- Các nhóm so sánh phải có phân phối chuẩn hoặc cỡ mẫu phải đủ lớn để được xem như tiệm cận phân phối chuẩn (n > 30).
- Phương sai của các nhóm so sánh phải đồng nhất, được kiểm tra thông qua kiểm định Levene Statistic, mức ý nghĩa lớn hơn 5% là điều kiện bắt buộc để đảm bảo giả định về sự đồng nhất phương sai giữa các nhóm phân loại.
Lưu ý: Nếu giả định tổng thể có phân phối chuẩn với phương sai bằng nhau không đáp ứng được thì bạn có thể dùng kiểm định phi tham số Kruskal-Wallis để thay thế cho ANOVA.
Để thực hiện Oneway ANOVA (Phân tích phương sai một yếu tố) chúng ta giả thuyết các đám đông này có cùng phương sai và có phân bố chuẩn.
CÁC BƯỚC PHÂN TÍCH ANOVA
Việc thực hiện kiểm định ANOVA gồm hai bước:
–Kiểm định phương sai đồng nhất với giả thuyết Ho: “phương sai của các nhóm là bằng nhau”, tức là xem xét phương sai của các nhóm so sánh có phải đồng nhất hay không: được kiểm tra thông qua kiểm định Levene Statistic, mức ý nghĩa lớn hơn 5% là điều kiện bắt buộc để đảm bảo giả định về sự đồng nhất phương sai giữa các nhóm phân loại. Do đó trước hết thực hiện kiểm định Levene test dùng để kiểm tra phương sai đồng nhất giữa các nhóm. Nếu Sig. Levene < 0,05 (5%) có nghĩa là phương sai giữa các nhóm không đồng nhất. Nếu Sig. Levene > 0,05 (5%) kết quả là phương sai giữa các nhóm đồng nhất và bước tiếp theo thực hiện kiểm định sự khác biệt trung bình giữa các nhóm bằng việc phân tích ANOVA.
– Phân tích ANOVA với giả thuyết Ho: “giá trị trung bình của các nhóm bằng nhau” (tức không có sự khác biệt nếu các nhóm. Kết quả phân tích ANOVA cho mức ý nghĩa quan sát (Sig.) < 0,05 (5%) thì có thể chứng tỏ có sự khác biệt (có ý nghĩa thống kê) về mức độ tác động của các nhóm phân loại của biến kiểm soát đối với khái niệm phụ thuộc. Ngược lại, Sig. ≥ 0,05 (5%) thì kết luận chưa có sự khác biệt có ý nghĩa thống kê về trị trung bình của các nhóm đối tượng quan sát (Hoàng Trọng và Chu Nguyễn Mộng Ngọc, 2008).
Khi thực hiện phân tích ANOVA, nếu kết quả kiểm định dẫn đến việc bác bỏ H0 thì ta tiếp ục làm tiếp phân tích sâu (Phân tích Post hoc) để xác định trung bình của nhóm nào khác biệt với nhóm nào.
CHUẨN BỊ DỮ LIỆU
Bộ dữ liệu của bạn cần bao gồm ít nhất hai biến (được biểu diễn dưới dạng các cột) phục vụ cho mục đích phân tích. Biến độc lập phải là biến phân loại (có thể là danh nghĩa hoặc thứ tự) và bao gồm ít nhất hai nhóm, trong khi biến phụ thuộc cần là biến liên tục (tức là được đo theo thang đo khoảng hoặc tỷ lệ). Mỗi hàng trong bộ dữ liệu cần đại diện cho một đối tượng hoặc đơn vị thí nghiệm duy nhất. Nếu bạn có một biến phân loại/nhân tố ở định dạng chuỗi/ký tự, bạn cần chuyển đổi nó thành một biến số được mã hóa trước khi tiến hành kiểm định.
HƯỚNG DẪN CHẠY TRÊN SPSS
Để thực hiện phân tích ANOVA một chiều trong SPSS, hãy nhấp vào Analyze > Compare Means > One-Way ANOVA.
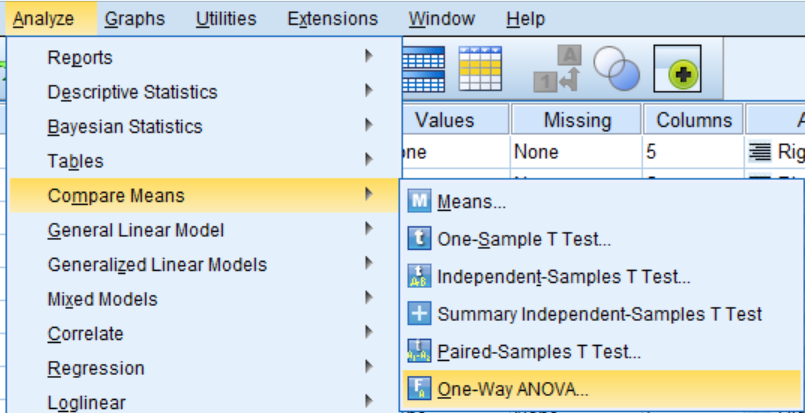
Cửa sổ One-Way ANOVA sẽ mở ra, cho phép bạn chỉ định các biến được sử dụng trong phân tích. Tất cả các biến trong bộ dữ liệu của bạn sẽ xuất hiện trong danh sách ở phía bên trái. Để di chuyển các biến sang bên phải, hãy chọn chúng trong danh sách và nhấp vào các nút mũi tên màu xanh. Bạn có thể di chuyển biến vào một trong hai khu vực: Dependent List (Danh sách biến phụ thuộc) hoặc Factor (Nhân tố).
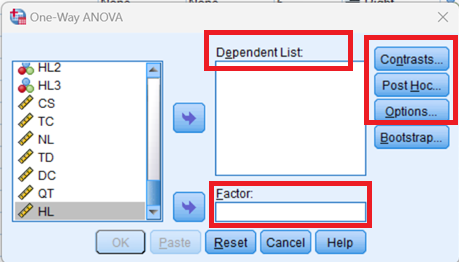
Trong đó :
- Dependent List: Đây là danh sách biến phụ thuộc. Biến này đại diện cho giá trị trung bình sẽ được so sánh giữa các nhóm mẫu. Bạn có thể thực hiện nhiều phép so sánh trung bình cùng lúc bằng cách chọn nhiều hơn một biến phụ thuộc. Biến phụ thuộc ở đây là biến định lượng.
- Factor: Đây là biến độc lập. Các danh mục (hoặc nhóm) của biến độc lập xác định các mẫu sẽ được so sánh. Biến độc lập phải có ít nhất hai nhóm, nhưng thông thường có từ ba nhóm trở lên khi sử dụng trong phân tích One-Way ANOVA.
- Contrasts: (Tùy chọn) Xác định các phép so sánh tương phản hoặc so sánh có kế hoạch được thực hiện sau khi kiểm định ANOVA tổng thể.
Khi kiểm định F ban đầu cho thấy có sự khác biệt có ý nghĩa thống kê giữa các trung bình nhóm, contrasts (so sánh tương phản) rất hữu ích để xác định trung bình cụ thể nào có sự khác biệt đáng kể, đặc biệt khi bạn có những giả thuyết cụ thể cần kiểm định. Các so sánh tương phản được quyết định trước khi phân tích dữ liệu (tức là a priori) và giúp phân tách phương sai thành các thành phần riêng lẻ.
So sánh tương phản có thể bao gồm việc sử dụng trọng số, so sánh không trực giao, so sánh tiêu chuẩn, và so sánh tương phản đa thức (phân tích xu hướng).
Có nhiều tài liệu trực tuyến và sách chuyên môn phân tích sự khác biệt giữa các tùy chọn này, giúp người dùng lựa chọn phương pháp tương phản phù hợp. Để tìm hiểu thêm về so sánh tương phản, bạn có thể mở hướng dẫn trợ giúp của IBM SPSS bằng cách nhấp vào nút “Help” ở cuối cửa sổ hộp thoại One-Way ANOVA.
4. Post Hoc: (Tùy chọn) Yêu cầu thực hiện các kiểm định hậu kiểm (post hoc, còn gọi là kiểm định so sánh bội). Các phương pháp hậu kiểm cụ thể có thể được chọn bằng cách đánh dấu vào các ô tương ứng.

- Equal Variances Assumed: Các phương pháp so sánh bội giả định tính đồng nhất của phương sai (tức là mỗi nhóm có phương sai bằng nhau). Để biết thêm chi tiết về từng phương pháp so sánh cụ thể, bạn có thể nhấp vào nút Help trong cửa sổ này.
- Test: Theo mặc định, kiểm định giả thuyết hai phía (2-sided hypothesis test) được chọn. Tuy nhiên, bạn cũng có thể thực hiện kiểm định một phía (one-sided hypothesis test) nếu sử dụng phương pháp hậu kiểm Dunnett. Để làm điều này, hãy chọn ô bên cạnh Dunnett, sau đó chỉ định nhóm đối chứng là nhóm đầu tiên hoặc cuối cùng (theo thứ tự số học) của biến phân nhóm. Trong khu vực Test, chọn < Control hoặc > Control. Tùy chọn kiểm định một phía yêu cầu bạn dự đoán rằng trung bình của nhóm đối chứng sẽ lớn hơn (< Control) hoặc nhỏ hơn (> Control) nhóm khác.
- Equal Variances Not Assumed: Các phương pháp so sánh bội không giả định phương sai bằng nhau giữa các nhóm. Để biết thêm thông tin chi tiết về từng phương pháp cụ thể, hãy nhấp vào nút Help trong cửa sổ này.
- Significance Level: Mức ý nghĩa thống kê mong muốn. Theo mặc định, mức ý nghĩa được đặt là 0.05.
Khi kiểm định F ban đầu cho thấy có sự khác biệt có ý nghĩa thống kê giữa các trung bình nhóm, kiểm định hậu kiểm (post hoc tests) rất hữu ích để xác định cặp trung bình cụ thể nào có sự khác biệt đáng kể, đặc biệt khi bạn không có giả thuyết cụ thể cần kiểm định. Kiểm định hậu kiểm so sánh từng cặp trung bình (tương tự kiểm định t-test), nhưng không giống như t-test, chúng điều chỉnh mức ý nghĩa để kiểm soát sai số khi thực hiện nhiều phép so sánh đồng thời.
- Options: Khi nhấp vào Options, một cửa sổ sẽ xuất hiện cho phép bạn tùy chỉnh các thống kê sẽ được hiển thị trong kết quả đầu ra, bao gồm:
- Descriptive: Thống kê mô tả của các nhóm.
- Fixed and random effects: Hiệu ứng cố định và ngẫu nhiên.
- Homogeneity of variance test: Kiểm định tính đồng nhất của phương sai (Levene’s test).
- Brown-Forsythe, Welch: Các kiểm định thay thế trong trường hợp phương sai không đồng nhất.
Ngoài ra, bạn có thể chọn hiển thị biểu đồ trung bình (Means plot) để trực quan hóa sự khác biệt giữa các nhóm.
Phần Missing Values cho phép bạn chỉ định cách xử lý các giá trị khuyết thiếu:
- Exclude cases analysis by analysis: Loại bỏ từng trường hợp thiếu dữ liệu khỏi từng phân tích riêng lẻ.
- Exclude cases listwise: Loại bỏ toàn bộ trường hợp nếu thiếu bất kỳ giá trị nào trong bộ dữ liệu.
Sau khi hoàn tất các tùy chọn, nhấp vào Continue để quay lại cửa sổ One-Way ANOVA và tiếp tục phân tích.

Sau đó, Click OK để chạy kiểm định One-Way ANOVA.
HƯỚNG DẪN ĐỌC KẾT QUẢ
Bước 1: Vào Analyze > Compare Means > One-Way ANOVA.
Bước 2: Đưa các biến định lượng và định tính cần kiểm định khác biệt vào để phân tích
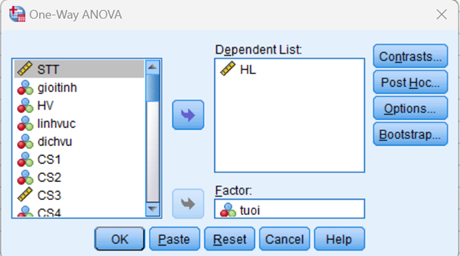
Bước 3: Trong mục Options, lựa chọn các thông số sau để hiển thị các kết quả cần đọc
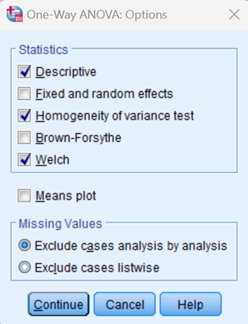
Bước 4 : Lựa chọn thêm Post hoc để kiểm định khác biệt trung bình giữa các nhóm (chỉ thực hiện khi Bảng ANOVA có giá trị sig. < 0.05
Và sau đây là demo việc đọc kết quả từ phân tích
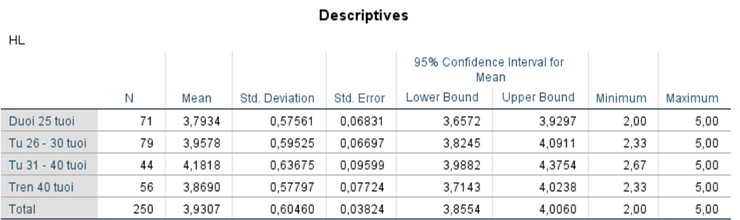
Thống kê mô tả
Bảng thống kê mô tả cho thấy mức độ hài lòng trung bình (Mean) của nhân viên có sự khác biệt giữa các nhóm tuổi. Cụ thể:
- Nhóm dưới 25 tuổi có mức độ hài lòng trung bình là 3.7934 (SD = 0.57561).
- Nhóm từ 26 – 30 tuổi có mức độ hài lòng trung bình là 3.9578 (SD = 0.59525).
- Nhóm từ 31 – 40 tuổi có mức độ hài lòng trung bình cao nhất, đạt 4.1818 (SD = 0.63675).
- Nhóm trên 40 tuổi có mức độ hài lòng trung bình là 3.8690 (SD = 0.57797).
Nhìn chung, nhóm nhân viên từ 31 – 40 tuổi có mức độ hài lòng cao hơn so với các nhóm còn lại.
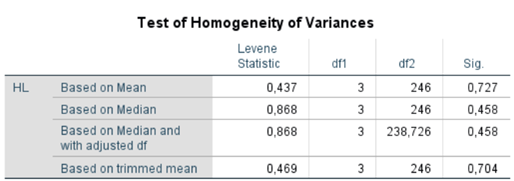
Kiểm định sự đồng nhất phương sai (Levene’s Test)
Kết quả kiểm định Levene cho thấy giá trị Sig. = 0.727 (dựa trên trung bình), cao hơn mức ý nghĩa 0,05. Điều này cho thấy phương sai giữa các nhóm tuổi không có sự khác biệt đáng kể, tức là giả định về sự đồng nhất phương sai được thỏa mãn. Do đó, phương pháp ANOVA một chiều có thể được sử dụng hợp lệ.
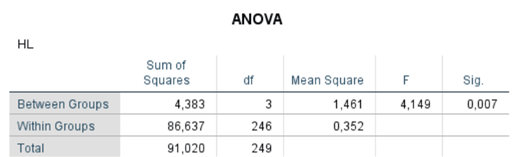
Kết quả kiểm định ANOVA
Kết quả phân tích phương sai một chiều (ANOVA) chỉ ra rằng có sự khác biệt có ý nghĩa thống kê trong mức độ hài lòng giữa các nhóm tuổi (F = 4.149, p = 0.007 < 0.05). Điều này cho thấy yếu tố độ tuổi có tác động đáng kể đến mức độ hài lòng của nhân viên.
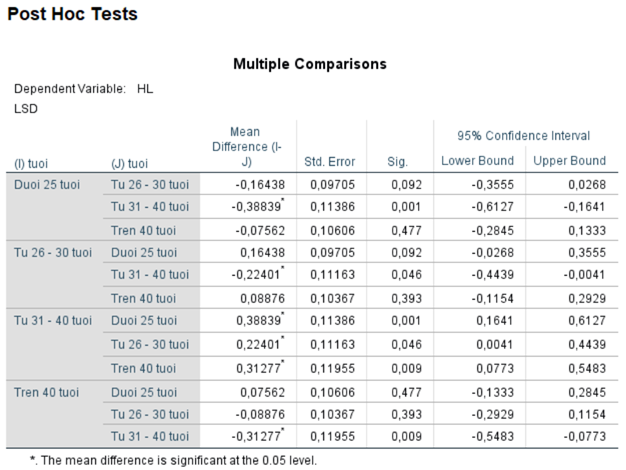
Kết quả so sánh từng cặp nhóm sử dụng phương pháp LSD cho thấy:
- Nhóm nhân viên từ 31 – 40 tuổi có mức độ hài lòng cao hơn đáng kể so với nhóm dưới 25 tuổi (Mean difference = 0.38839, p = 0,001).
- Nhóm nhân viên từ 31 – 40 tuổi cũng có mức độ hài lòng cao hơn so với nhóm từ 26 – 30 tuổi (Mean difference = 0.22401, p = 0.046).
- Nhóm trên 40 tuổi có mức độ hài lòng thấp hơn nhóm 31 – 40 tuổi (Mean difference = -0.31277, p = 0.009).
Tuy nhiên, sự khác biệt giữa các nhóm còn lại không có ý nghĩa thống kê
Kết luận
Kết quả phân tích ANOVA cho thấy độ tuổi có ảnh hưởng đến mức độ hài lòng của nhân viên. Nhóm nhân viên từ 31 – 40 tuổi có mức độ hài lòng cao nhất, trong khi nhóm dưới 25 tuổi và trên 40 tuổi có mức độ hài lòng thấp hơn. Sự khác biệt này có thể xuất phát từ kinh nghiệm làm việc, kỳ vọng nghề nghiệp và các yếu tố liên quan đến sự phát triển trong công việc. Các nhà quản lý nên cân nhắc điều chỉnh chính sách nhân sự phù hợp để cải thiện mức độ hài lòng của nhân viên thuộc các nhóm tuổi khác nhau.
CÁC THUẬT NGỮ TRONG ANOVA:
Sum of squares: Tổng các chênh lệch bình phương
Within-groups sum of squares: Tổng các chênh lệch bình phương trong nội bộ nhóm:
Between-groups sum of squares: Tổng các chênh lệch bình phương giữa các nhóm
Total sum of squares: Tổng các chênh lệch bình phương toàn bộ





